Mutual exclusion and caching using Redis
Motivation
There is a client that needs to display five items to the user. The client renders them using HTML. We will call this event items display. The items being displayed belong to a list. All five items of the list are calculated in one go on the server, and the items are all distinct: each one has a different image and clicking each one should lead to a different web page.
Therefore, a separate HTTP request is made in order to display an item on position p of the list. A request retrieves two URLs:
- the image URL (image available on a CDN) and
- the link destination URL.
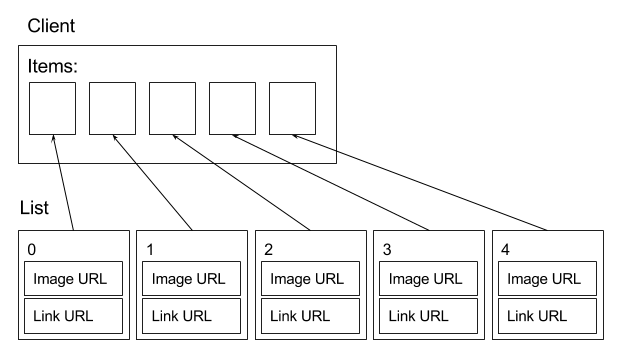
Simultaneous requests and list caching
All the positions’ requests are made simultaneously. The request arriving first should perform the calculation and cache the five-item list. The item list is calculated once and cached for two reasons. The first one is that the calculation is expensive and the second one is the possibility of duplicates (explained below). After it’s cached, the same list should be used by the remaining four requests. A request for the item at position p will get the whole list and will just use the element at position p. It’s even possible that a client decides to take only the first three items and disregards the last two.
Fear of duplicates
The list could be recalculated on every request, but this is something we’d avoid because the calculation is expensive. Furthermore, it can lead to duplicates being shown.
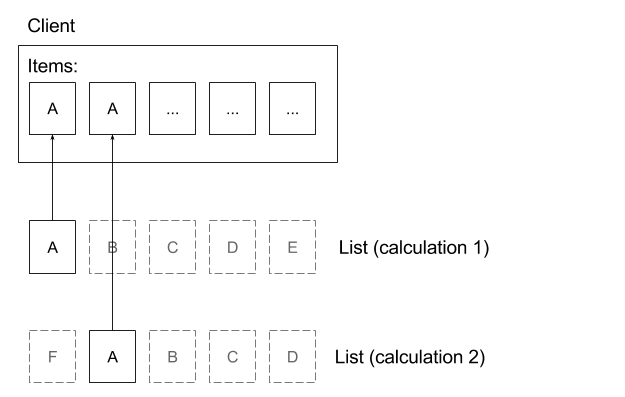
Duplicates are possible because the calculation can return different item lists if run at different points in time. This happens because items become available or unavailable in real time. In other words, an item in position 1 in the list can appear at position 2 if the list is recalculated a bit later.
Server is horizonally scaled
The requests coming at the same moment from an items display first hit a load balancer. Since there are many clients making requests to the server, the server is horizontally scaled and sits behind a load balancer. If we don’t intervene and the requests are left to be distributed by the LB, our caching scheme will not work.
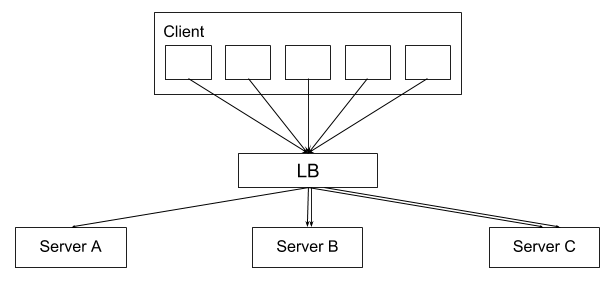
At a certain moment a client will make five requests with the same parameters. Only the item position will differ between these five requests. Each request gets the list, extracts the element at position p and returns it to the client. The order in which the requests are received by the servers is unknown. Some requests might even come very late.
Load balancer stickyness solution
The list can be cached in the server application. A precondition for this that all the requests coming from the same (client, params) pair are forced to the same machine. This can be achieved by configuring the load balancer to load balance on OSI layer 7, i.e. to balance based on a header value extracted from the HTTP message.
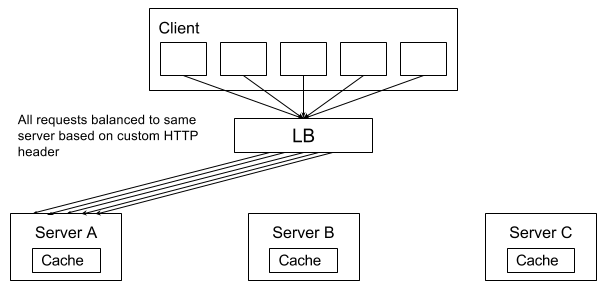
The load balancer stickyness solution works well, but dictates two things: the server must be stateful, as it contains the cache, and the load balancer must forward all requests onto the same machine.
While cache is not a big issue, sticky load balancing is not always possible. Not all load balancers provide customizable layer-7 load balancing. For example, Amazon’s Elastic Load Balancer offers layer-7 balancing via stickiness based on the ELB’s own cookie that is set on the client only after the first response was already received. In other words, ELB is not able to make requests sticky to a machine a priori, i.e. based on a custom header or cookie. As the use case that inspired this write-up included the ELB, other options were explored.
Redis solution
As LB stickiness is not always feasible, the requirements need to be satisfied in a different way. Since without stickiness servers will effectively be receiving requests in a non-deterministic way, they need to either coordinate themselves or be coordinated by a separate entity. In this solution we implement the coordination with an external service that will:
- decide which request will do the calculation and
- cache the list
We could implement such a service from scratch, but Redis lends itself pretty well to the purpose.
Design
Instead of forcing every request onto the same machine, we will allow them to go freely to any machine, at the LB’s discretion.
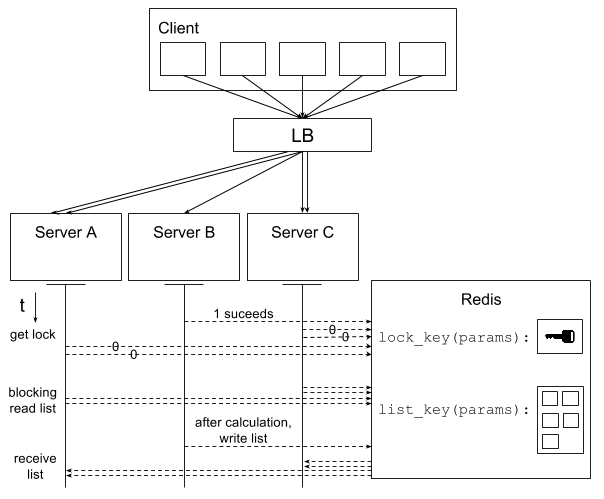
Every request will attempt to get a lock in Redis, but only one should succeed. The one that acquires the lock will calculate the list, while the others will proceed to do a blocking read on the cache. After the request with the lock is done calculating, he’ll write the list into the cache and the blocking requests will read it.
Since multiple clients are performing items displays, there will be many concurrent locks and cached lists in Redis.
Every request needs to know which lock and list it should interact with. This can be done by generating Redis keys for
the lock and list based on the the items display params. This way different items displays will be kept independent.
We can use a convention of naming these Redis keys lock_key(params) and list_key(params).
The idea is described in the picture below.
Design assumptions
- Lock must persist at least until all requests of an items display have read the cached list.
- Lock must expire before list.
- Redis cache must be big enough with regard to the expected request rates.
Implementation
The keys are generated with a rule similar to:
lock_key(params) = "lock-" + concat(params)
list_key(params) = "list-" + concat(params)
A request thread will attempt to get a lock by setting an arbitrary value into lock_key(params) by doing a
HSETNX lock_key(params) "lock" "got it"
EXPIRE lock_key(params) lock_ttl
The HSETNX commands writes a field “lock” with the value “got it” to the key, and returns 1 only if the the field there did not already exist. Basically, just the first write gets a 1 and any subsequent ones get a 0. This covers the decision on who will calculate the list.
After the lock-winning thread is done with the calculation, it will write the item list with the command:
LPUSH list_key(param) list_json
EXPIRE list_key(params) list_ttl
The non-lock-winning threads carry on and try to execute a blocking read on the list, but it is not yet there, so they wait. Since there are multiple requests trying to read, we cannot use the typical Redis pop commands, as that would mean the first thread would remove the list and the remaining threads would fail with a timeout. Instead we keep the item list in a one-element circular list using BRPOPLPUSH. Every thread reads the list with the following command:
list_json = BRPOPLPUSH list_key(param) list_key(param)
EXPIRE list_key(params) list_ttl
Both the lock and list entries have their expiry times explicitly set, with lock_ttl < list_ttl, in order to satisfy the second design assumption listed in the section above.
Conclusion
The algoritm has been tested locally with a small number of requests competing for the Redis lock and data. More extensive tests in real production conditions are to follow. I will report on these as soon as they are available.
Some issues may arise with this approach. For example, the Redis cache could become too small if the traffic increases sufficiently. This could lead to items display not being able to create a single lock or to write a list.
Additionally, Redis operations could time out and result in either a single item not being shown or none of them being shown, e.g. in case the lock-acquiring request fails.
I am not very familiar with the Redis implementation of its default LRU eviction strategy. This algorithm assumes that Redis will respect expiry times set on keys. Even if this is not the case, for every the lock access, a list access had to have happened later, so LRU eviction should work as expected.
Not having a lot of experience with Redis, I may have missed some obvious features that would help simplify the algorithm, so I would like to welcome comments on the post!
I hope to get some time soon to publish my Java implementation of this.